Camael's note
Search
Share
Camael's note
운영체제
데이터 중심 애플리케이션 설계
About Me
Elastic Search
kubernetes in action
Search
포스트
🪩
Gleam: for 문을 recursion 으로 대체하기
2024/04/20
🪩
Gleam: for 문을 recursion 으로 대체하기
2024/04/20
Gleam: Case Expressions (if, when)
2024/04/18
Gleam: Case Expressions (if, when)
2024/04/18
Gleam: Ints, Floats, Modules
2024/04/15
Gleam: Ints, Floats, Modules
2024/04/15
Copilot Error: unable to get local issuer certificate 에러 해결하기 (회사에서 copilot, intellij 사용하기, 로그인이 안될 때)
2024/02/21
Copilot Error: unable to get local issuer certificate 에러 해결하기 (회사에서 copilot, intellij 사용하기, 로그인이 안될 때)
2024/02/21
파티셔닝의 방법과 구현, 알고리즘 알아보기
2024/01/23
파티셔닝의 방법과 구현, 알고리즘 알아보기
2024/01/23
ThreadLocal이란 무엇인가? JNI를 열어서 확인해보자
2023/10/02
ThreadLocal이란 무엇인가? JNI를 열어서 확인해보자
2023/10/02
Rust의 Variables, mutability, shadowing, constants
2023/09/16
Rust의 Variables, mutability, shadowing, constants
2023/09/16
Rust의 Functions, parameters, statement, expressions
2023/09/16
Rust의 Functions, parameters, statement, expressions
2023/09/16
Rust 의 if Expressions
2023/09/16
Rust 의 if Expressions
2023/09/16
MySQL의 record lock과 isolation level의 실제 동작(ANSI와 다른 동작) shared, exclusive lock?
2023/09/02
MySQL의 record lock과 isolation level의 실제 동작(ANSI와 다른 동작) shared, exclusive lock?
2023/09/02
Java의 ByteBuffer란 무엇일까? 자바에서 시스템 메모리를 사용할 수 있는 Buffer class 살짝 보기
2023/07/22
Java의 ByteBuffer란 무엇일까? 자바에서 시스템 메모리를 사용할 수 있는 Buffer class 살짝 보기
2023/07/22
트랜잭션을 이해하기 위한 기반지식 어떻게, 어디에 저장되는 걸까?
2023/07/18
트랜잭션을 이해하기 위한 기반지식 어떻게, 어디에 저장되는 걸까?
2023/07/18
트랜잭션이란? ACID의 구체적인 사례로 Transaction을 이해해 보자(with MySQL)
2023/07/15
트랜잭션이란? ACID의 구체적인 사례로 Transaction을 이해해 보자(with MySQL)
2023/07/15
Heap dump 분석하기(Out of memory Error가 발생했을 때)
2023/06/11
Heap dump 분석하기(Out of memory Error가 발생했을 때)
2023/06/11
MongoDB local에 docker-compose로 띄우고 mongo-express로 보기
2023/05/01
MongoDB local에 docker-compose로 띄우고 mongo-express로 보기
2023/05/01
ArrayList : 어떤 interfacce를 구현했을까? - java collection 깊게 보기 - 0010
2023/02/06
ArrayList : 어떤 interfacce를 구현했을까? - java collection 깊게 보기 - 0010
2023/02/06
세션과 쿠키의 차이점, 그리고 JWT token: session vs cookie vs JWT token
2023/02/05
세션과 쿠키의 차이점, 그리고 JWT token: session vs cookie vs JWT token
2023/02/05
Collection hierarchy in java concepts, 자바 collection 깊게 보기 - 0001
2023/02/02
Collection hierarchy in java concepts, 자바 collection 깊게 보기 - 0001
2023/02/02
Kotlin extensions 사용하기 코틀린을 확장하여 Util class를 제거해보자.
2022/12/21
Kotlin extensions 사용하기 코틀린을 확장하여 Util class를 제거해보자.
2022/12/21
347. Top K Frequent Elements 풀이, Bucket sort 를 사용하다
2022/12/14
347. Top K Frequent Elements 풀이, Bucket sort 를 사용하다
2022/12/14
Kotlin, LoggerFactory is not a Logback LoggerContext 에러 해결, SLF4J 와 Log에 관하여
2022/12/12
Kotlin, LoggerFactory is not a Logback LoggerContext 에러 해결, SLF4J 와 Log에 관하여
2022/12/12
BigQuery Springboot 연동, Multi-result 와 Stored procedure 사용하기
2022/11/18
BigQuery Springboot 연동, Multi-result 와 Stored procedure 사용하기
2022/11/18
2의 보수란 무엇인가? 왜 컴퓨터는 2의 보수를 사용할까? what is two’s complements
2022/11/02
2의 보수란 무엇인가? 왜 컴퓨터는 2의 보수를 사용할까? what is two’s complements
2022/11/02
Clustering Index 란 무엇인가? InnoDB의 Clustered Index를 알아보자.
2022/10/29
Clustering Index 란 무엇인가? InnoDB의 Clustered Index를 알아보자.
2022/10/29
Kinesis stream에서 중복 메시지가 오면 어떻게 대응해야 할까?
2022/10/26
Kinesis stream에서 중복 메시지가 오면 어떻게 대응해야 할까?
2022/10/26
Java map compute current value without if statement
2022/10/10
Java map compute current value without if statement
2022/10/10
K8S Helm quick start, the package manager
2022/10/06
K8S Helm quick start, the package manager
2022/10/06
OAuth2 Access Tokens
2022/10/01
OAuth2 Access Tokens
2022/10/01
AWS Kinesis data stream Terminology 아마존 kinesis 용어정리
2022/09/30
AWS Kinesis data stream Terminology 아마존 kinesis 용어정리
2022/09/30
Two Sum II - Input Array Is Sorted(sorted in non-decreasing order)
2022/09/27
Two Sum II - Input Array Is Sorted(sorted in non-decreasing order)
2022/09/27
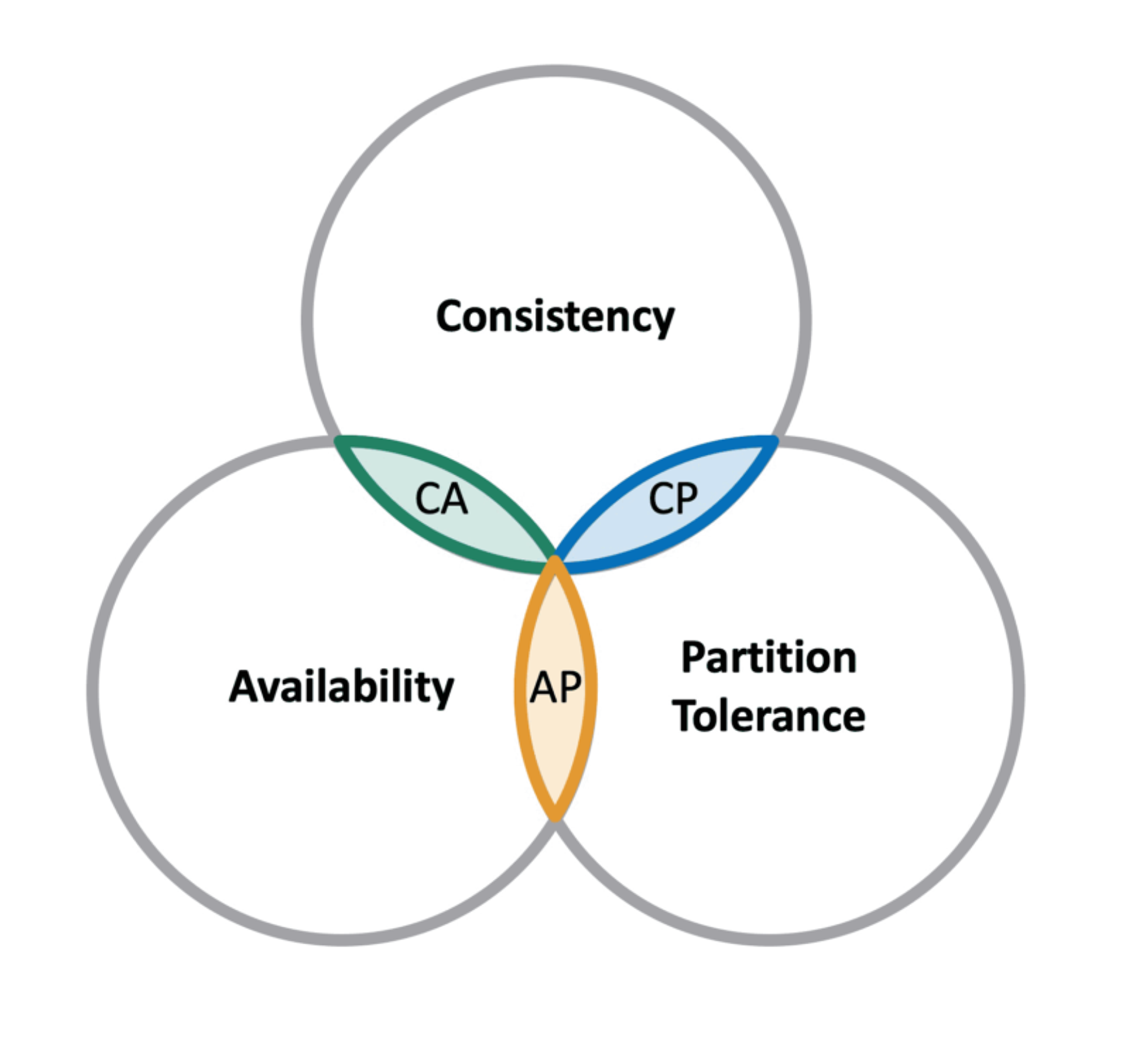
CAP 정리, Consistency, Availability, Partition Tolerance theorem, DB별 CAP
2022/09/23
CAP 정리, Consistency, Availability, Partition Tolerance theorem, DB별 CAP
2022/09/23
AWS EKS, Kubernetes Health check, Livness probe & Readiness probe
2022/09/22
AWS EKS, Kubernetes Health check, Livness probe & Readiness probe
2022/09/22
What’s different ALB and NLB(AWS 의 ALB, NLB 차이점)
2022/09/20
What’s different ALB and NLB(AWS 의 ALB, NLB 차이점)
2022/09/20
Java 14 Record keyword 는 무엇인가
2022/09/08
Java 14 Record keyword 는 무엇인가
2022/09/08
스프링의 @ConfigurationProperites 의 정확한 사용법, properties 읽어오기
2022/09/07
스프링의 @ConfigurationProperites 의 정확한 사용법, properties 읽어오기
2022/09/07
ArgoCD private(Enterprise) repo 등록
2022/09/02
ArgoCD private(Enterprise) repo 등록
2022/09/02
Docker 튜토리얼 nginx 컨테이너 만들기
2022/08/31
Docker 튜토리얼 nginx 컨테이너 만들기
2022/08/31
Spring boot 에 caffeine 캐시를 적용해보자 - 어떻게하면 일을 안 할까?
2022/08/31
Spring boot 에 caffeine 캐시를 적용해보자 - 어떻게하면 일을 안 할까?
2022/08/31
Jpa Entity 의 Equals, 객체 동일성과 동등성, Lombok 을 써도 될까?
2022/07/26
Jpa Entity 의 Equals, 객체 동일성과 동등성, Lombok 을 써도 될까?
2022/07/26
Floyd’s Cycle-Finding Algorithm
2022/07/25
Floyd’s Cycle-Finding Algorithm
2022/07/25
Tree 의 Inorder 와 재귀호출
2022/07/19
Tree 의 Inorder 와 재귀호출
2022/07/19
가비지 수집 기초 GC의 기본개념
2022/03/02
가비지 수집 기초 GC의 기본개념
2022/03/02
User Agent 정말 믿어도 되는걸까? (믿지마라)
2021/12/15
User Agent 정말 믿어도 되는걸까? (믿지마라)
2021/12/15
binary search 시간 복잡도 수학적 증명
2021/11/03
binary search 시간 복잡도 수학적 증명
2021/11/03
Docker network xxxxxxx not found Error
2021/09/23
Docker network xxxxxxx not found Error
2021/09/23
JVM과 하드웨어, 운영체제
2021/08/16
JVM과 하드웨어, 운영체제
2021/08/16
컴퓨터의 계산 (나눗셈은 왜 느릴까?) 나누기 연산의 이해
2021/08/11
컴퓨터의 계산 (나눗셈은 왜 느릴까?) 나누기 연산의 이해
2021/08/11
kotlin 에서 stream 을 지워보자, kotlin 함수를 사용하기
2021/08/11
kotlin 에서 stream 을 지워보자, kotlin 함수를 사용하기
2021/08/11
JVM 이야기 (Overview of the JVM)
2021/08/01
JVM 이야기 (Overview of the JVM)
2021/08/01
싱글턴 패턴에 serializable 적용하기
2021/07/31
싱글턴 패턴에 serializable 적용하기
2021/07/31
Load more